
영어의 regular expression 을 우리말로 번역한 것에 불과하다.
원초적으로 영어로 풀어보자.
사람보고 regular라고 하면 단골이라는 뜻이 된다. 그만큼 자주 오는 사람을 regular라고 한다. 그러니까 regular는 '자주' 또는 '정기적으로' 반복되는 기본 그림을 가지고 있다.
그럼 regular expression에서 regular의 비밀은 풀린셈이다. '자주' 또는 '정기적으로' 반복되는 expression이라는 말이니까.
expression은 뭔가? 단어대 단어로 번역을 하면 '표현'이 된다. 사람의 생각 따위를 말로 표현하는게 expresssion이다.
근데 regular expression에서 expression은 이외에도 '수식'이라는 의미가 담겨져 있다.
이딴거다.
x = y + z
이런게 수식이다.
그러니까 간단히 정리하면 정규식(regular expression)이란 텍스트 (아무리 간단하고 짧은 텍스트라도)에서 반복적으로 나타나는 표현을 특별한 방법으로 수식화해 놓은 걸 말한다.
간단히 정리해도 어려울 수밖에 없다. 직접 봐야 이해가 빠를거다.
한가지 예를 들어보자.
"넌 핸폰 어디꺼써? 011? 016? 난 이제 010쓰는데. 뭐? 017? 아니, 아직도 017이 있니? 그렇구나..."
누군가 이런 말을 계속 반복한다고 생각해 보시라.
패턴이 느껴지는가?
패턴은 반복을 통해 느껴진다고 했다. 예를 들어, 그냥 011 하나가지고는 패턴이라 할 수 없다는 거다. 011, 016, 010 식으로 계속되다보면 짱구 굴리는 호모사피엔스는 자연스럽게 패턴을 인식한다.
원본 텍스트: "넌 핸폰 어디꺼써? 011? 016? 난 이제 010쓰는데. 뭐? 017? 아니, 아직도 017이 있니? 그렇구나..."
패턴 인식: 011 016 010 017 등 숫자 세개가 합쳐진 표현
패턴 인식은 말 그대로 우리 머리속에서 일어나는 일이다. 그걸 우리가 이해하기 쉽게 풀어써 놓은 거다.
컴퓨터는 저런말 못알아듣는다. 단 한치의 오차도 허용하지 않는 아주 지독하게 융통성 없는 꽉막힌 기계이기 때문에 또박또박 알려줘야 한다.
컴쟁이들은 바로 저런 패턴 인식을 컴퓨터에게 한치의 오차도 없이 알려주기 위해 정규식이라는 걸 만들어 놓았다는 말이다.
저 패턴 인식을 컴퓨터가 알아들을 수 있는 정규식으로 표현하면 다음과 같다.
찾기 패턴: [0-9][0-9][0-9]

[] 이 괄호는 범위를 표시한다. 이 괄호속에 들어가 있는 문자 중 하나만 맞으면 그만이라는 거다. 그러니까, [abc][abc][abc]라면 aaa, aab, ccc, abc 이딴거 다 찾지만 adc는 건너뛴다. 'd'는 'abc'에 포함되지 않으니까.
[0123456789] 이렇게 쓰면 한자리로 된 모든 숫자를 뜻하겠지? 근데 컴쟁이들이 누구라고 했는가. 이딴거 못참는다. 씰데없이 '0123456789' 이렇게 왜 쓰냐는 말이다. '0-9'하면 될걸. 그래서 [0-9]라고만 해도 읽히는대로 '0에서 9까지'로 알아듣게 정규식을 만든거다.
다시 말해, 순서가 정해져 있는 숫자나 알파벳의 경우 '-'로 범위를 지정해줄 수 있다는 말이다. [0-9]면 모든 한자리 숫자를 말하고, [a-z]라고 하면 (대소문자를 구별할 경우) 모든 알파벳 소문자 한개를 뜻한다. 물론, 대소문자를 구별할 때 모든 알파벳이라고 하려면 [a-zA-Z]라고 쓸 수도 있다. 여기에 숫자까지 더해 [0-9a-zA-Z]라고 해주면 숫자 한자릿수 또는 모든 알파벳 한개라는 뜻이 된다.
문제 하나 내보자.
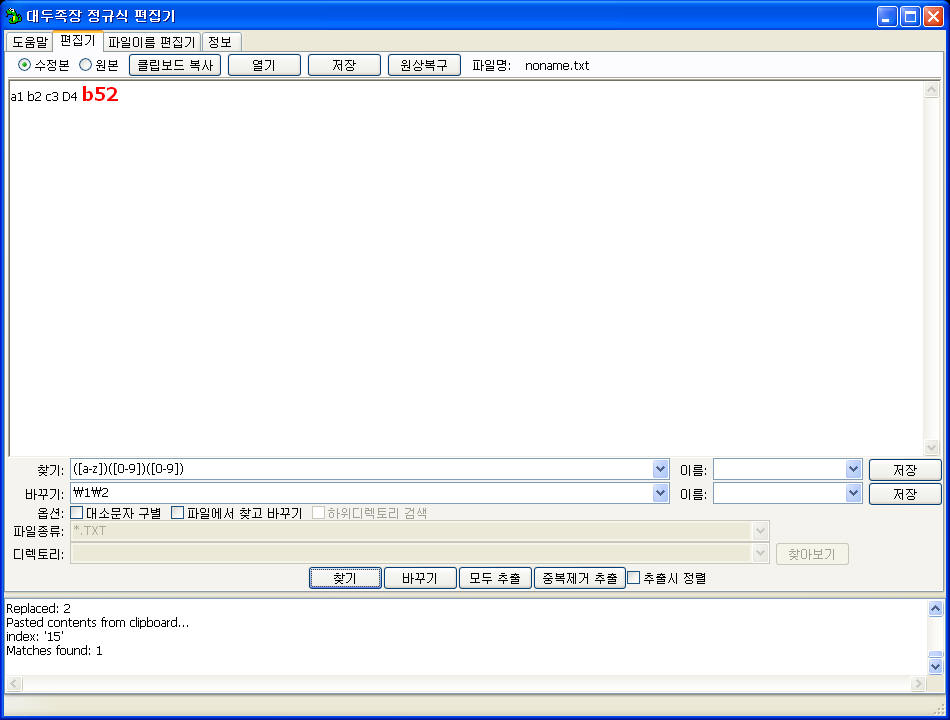
문제: "문서를 읽다보면 a1, b2, c3, D4, b52 식으로 표시가 된 부분이 있습니다. 그런데 b52 식으로 숫자가 두개인 경우는 잘못된 표기이니 앞자리만 남기고 뒷자리 숫자는 지워주세요. b52라면 b5라고 바꿔주면 됩니다."
무지 큰 문서에 이런식으로 영문+숫자 표시가 계속 반복돼 나타나는대 a1, b2, c3 처럼 알파벳 1개와 숫자 1개만 옳은 표기이고 숫자가 두개인것은 모두 잘못된 표기라고 한다. 잘못된 표기만 찾아내려면 어떻게 해야할까? 요게 퀴즈다.
찾기 패턴: [a-z][0-9][0-9]
요렇게 해주면 "a1 b2 c3 D4 b52" 중에서 b52만 찾아낸다. []가 3개 반복되는데 첫번째는 알파벳 1개를 가리키고 뒤따르는 두개는 숫자 하나씩이니까 결국 알파벳 1개와 숫자두개로 만들어진 표현 패턴만 찾게 된다.따라서 a1 은 알파벳 1개+숫자한개 이므로 이 조건을 만족시키지 않으니까 건너뛴다.
그럼 이번엔 () 괄호까지 더해보자.
응용 찾기 패턴 1: ([a-z][0-9][0-9])
() 의 의미는 찾은 걸 기억하라는 거다. 찾은 걸 기억해서 바꾸기에서 활용해 달라는 정규식 약속을 뜻한다.
찾기 패턴에서 여러개의 괄호를 사용해 찾은 부분을 여러개로 나눠 기억하도록 할 수도 있다. 이렇게 말이다.
응용 찾기 패턴 2: ([a-z])([0-9])([0-9])
괄호로 기억한 부분은 바꾸기 패턴에서 \1, \2, \3... 식으로 참조할 수 있다. (\ 의 의미에 대해서는 다음회에 다룬다. 여기서는 그냥 \1이 첫번째 괄호로 기억한 내용, \2가 두번째 괄호로 기억한 내용이라는 것만 염두에 두면 된다.)
그럼 짱구를 굴려보자. b52 식의 표시가 잘못된 거고 첫번째 숫자만 남기고 두번째 숫자는 날려버려야 한다고 했다. 그러니까 b52 는 b5 가 돼야 하고, c89 는 c8 이 돼야 한다는 거다. 그럼 응용 찾기 패턴 2를 사용하고 바꾸기 패턴에서 이렇게 해주면 그만이다.
바꾸기 패턴: \1\2
이게 뭔 말일까? b52를 예로 들어 컴퓨터가 하는 짓을 순서대로 들여다 보자.
1. 찾기 패턴으로 b52 라는 표현을 찾아낸다. ([a-z][0-9][0-9] 니까 알파벳 한개+숫자 2개가 반복되는 표현을 찾는다.)
2. 알파벳 1개와 숫자 한개, 숫자 한개에 각각 괄호를 쳐줬으니까 따로 따로 기억한다. (b), (5), (2) 를 3개로 나눠 기억한다는 말이다.
3. 바꾸기 패턴을 보니 \1\2라고 돼 있다. 2번에서 기억한 b와 5 에 해당한다. 2는 바꾸기 패턴에 들어가 있지 않으므로 버린다. (\1 = b, \2 = 5, \3 = 2 였는데 \3를 바꾸기 패턴에 집어넣지 않았으므로 날려버리는 결과라는 거다.)
4. b5 만 남겨둔다.

이게 정규식의 파워다.
요기서 한가지 헷갈릴 수 있는 부분을 짚고 넘어가자. b52를 찾았서 \1\2로 b5만 바꿨는데 왜 2가 사라지느냐고 고민할 수 있다. 요거 기억하시라.
1. 정규식으로 찾아낸 패턴은 일단 문서에서 패턴 전체를 뜯어낸다.
2. 정규식 바꾸기 패턴에서 가공해 나온 표현을 그 뜯어낸 부분에 갖다 붙인다.
다시 말해, b52 를 [a-z][0-9][0-9]란 패턴으로 찾아냈으면 문서에서 b52 라는 전체를 뜯어내고 바꾸기 패턴에서 \1\2를 해줬으니까 b5만 남을테고 그 남은 결과를 찾기 패턴을 뜯어내서 구멍이 난 부분에 갖다 붙인다는 말이다.
3단계로 눈으로 보여주겠다.
1. 원본 텍스트: "b52제품"
2. 찾기 패턴으로 b52를 찾아서 떼어낸다: "___제품" (밑줄은 그 자리가 비어있다는 의미지 밑줄치는 게 아니다ㅡ.,ㅡ)
3. 바꾸기 패턴에서 \1\2로 남겨진 b5를 원본 텍스트 빈자리에 채워넣는다: "b5제품"
이제 이해가 갈거다.
조금 현실적인 예로 응용해볼까?
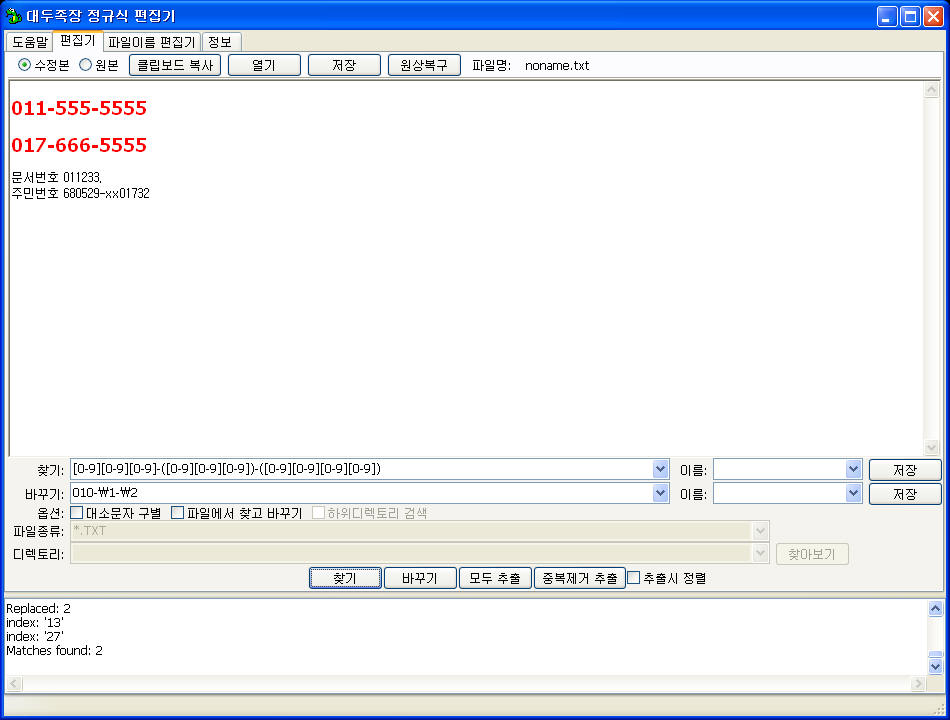
문제: 이동통신사 대리점에서 고객의 전화번호 1만개를 가지고 있는데 이통사 식별번호를 모두 010으로 통일하려고 한다. 011, 017, 016, 018 식으로 이통사 식별번호가 다르고 전화번호는 011-555-5555 식으로 돼 있다고 가정한다. (국번 4자리도 상관없지만 이건 나중에 정규식 좀더 배우고 나서 할 수 있다.)
이런 문제 역시 정규식 없으면 맨땅에 헤딩이요, 삽질로 날밤까야할 판이다.
최소한 정규식에 대한 삘이라도 있는 사람이면 '정규식이라는 거 사용하면 될텐데...' 라는 고민이라도 하게 된다.
패턴 인식: 011-555-5555 식의 핸드폰 전화번호는 숫자 3개 + '-' + 숫자 3개 + '-' + 숫자 4개라는 패턴을 갖고 있다.
핸드폰 찾기 패턴: [0-9][0-9][0-9]-([0-9][0-9][0-9])-([0-9][0-9][0-9][0-9])
요기서 잠깐. '-'라는 문자는 []에서 '0-9','A-Z'식의 연속성을 갖는 숫자나 문자 범위를 지정할때만 '특별한 의미'를 갖고 그 이외에는 문자 그대로 받아들인다. 바로 이 '특별한 의미'라는 걸 다음회에 설명한다. 앞에 나온 \ 라는 문자도 '특별한 의미'와 관련이 있다.
핸드폰 찾기 정규식을 보면 괄호를 두군데 썼다. 이동통신사 식별번호에 해당하는 맨앞 숫자 세자리만 빼고 국번과 전화번호 부분만 기억하라는 말이다. 그러니까 '011-555-5555'에서 '011' 부분은 뺴고 '555'랑 '5555'만 기억해서 바꾸기에서 활용하겠다는 뜻이다.
바꾸기 패턴: 010-\1-\2
이통사 식별번호는 010 으로 통일하기로 했으니까 찾기할때 기억할 필요가 없다. \1과 \2는 찾기 패턴에 나온 괄호로 감싼 부분을 가리키니까 \1 는 첫번째 괄호로 감싼 국번, \2는 두번째 괄호로 감싼 전화번호 부분이 된다.
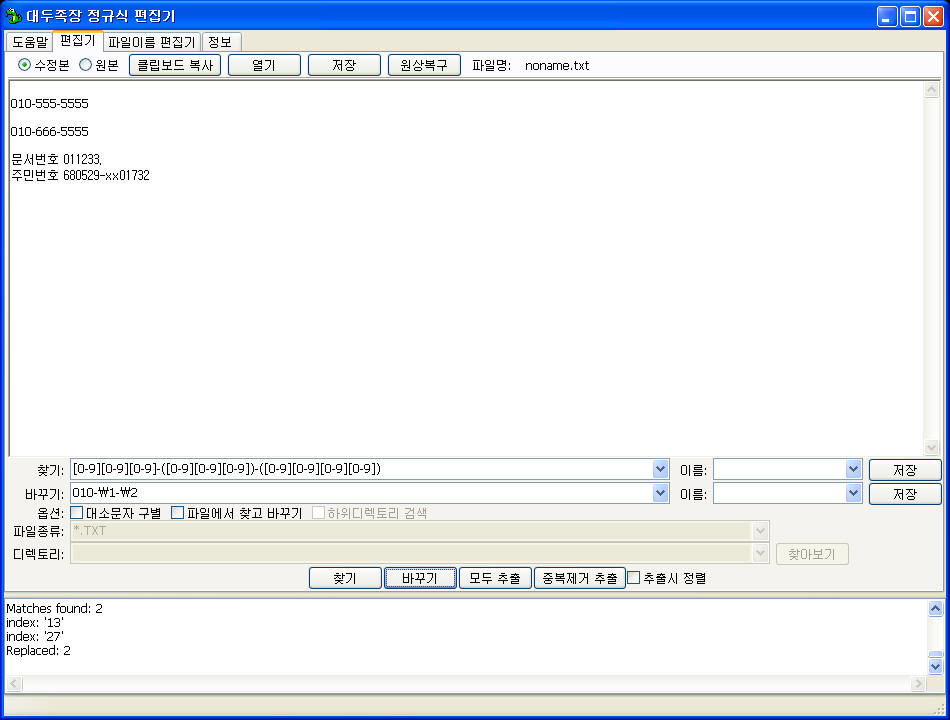
결국 '011-555-5555'는 '010-555-5555'가 된다는 말이다.
또, 짱구 잘못굴린 사람은 이렇게 생각할 수도 있다.
"에이... 그냥 011, 016, 017, 018 찾아서 010으로 바꿔주면 되잖어. 이통사 식별번호 몇개나 된다구... 저게 더 시간 많이 걸리겠다."
글타. 그래도 된다.
근데...
그건 뻘짓이다. 왜냐구?
문서에 만약 "0101" 이런식으로 다른 부분에도 이통사 식별번호와 관련없이 010이나 011 등이 들어가 있는 부분이 있다면 거기까지 싹 바꿔버리는 뻘짓을 하게 된다는 말이다.
"문서번호 01123." -> "문서번호 01023."
정규식이 막강한 이유는 원하는 부분을 콕 짚어낼 수 있다는 데 있다. 또, 원하는 부분만 콕 짚어서 원하는 부분만 바꿀 수도 있다. (물론, 그만큼 정규식을 잘못활용하면 역시 뻘짓하기 쉽다. 제대로 알고 조심해서 쓸수록 빛을 발하는게 정규식이다.)
이게 정규식의 빠우어~다.
맛보기는 이정도로 하고 다음번에는 정규식 기초중에 기초라고 할 수 있는 '문자'의 의미에 대해서 알아보기로 한다.
'JAVA > regex 정규표현식' 카테고리의 다른 글
| 대두족장 정규식 편집기 프로젝트 (0) | 2014.10.28 |
|---|---|
| 패턴 인식 5.5 - 응용문제 (0) | 2014.10.28 |
| 패턴 인식 5 - 골라 골라~ (0) | 2014.10.28 |
| 패턴 인식 4 - 보이는 것과 보이지 않는 것 (0) | 2014.10.28 |
| 패턴 인식 2.5 - pop quiz! (0) | 2014.10.28 |
| 패턴 인식 2 - 정규식이란? (0) | 2014.10.28 |
| 패턴 인식 1 - 패턴이란? (0) | 2014.10.28 |
| 정규 표현식(Regex) 강좌 9편. 전후방탐색(lookaround) (0) | 2014.10.28 |

nineDeveloper
안녕하세요 현직 개발자 입니다 ~ 빠르게 변화하는 세상에 뒤쳐지지 않도록 우리모두 열심히 공부합시다 ~! 개발공부는 넘나 재미있는 것~!