
여기서 "제대로 된"이라는 의미는 에디터가 훌륭하다는 게 아니라 정규식 기능만큼은 할 거 다한다는 의미다.
예를들어, 대두족장 정규식 편집기는 편집기 기능으로서는 UltraEdit의 발뒤꿈치도 못따라간다.
근데... 무슨 이유에선지 UltraEdit 의 정규식 찾고 바꾸기 기능만큼은 거꾸로 허접한 대두족장 정규식 편집기보다 못하다.
Geek Alert! UltraEdit의 정규식 기능은 못한 정도가 아니라 사실, 한참 모자란다. 물론, 그 모자라는 기능만으로도 웬만한 건 다 할 수 있기 때문에 여러분에게 소개한 거다. 하지만, 고급 기능을 알고나면 아쉬움이 많아진다. UltraEdit나 기타 윈도우용 프로그램이 정규식 분야에서 헤매는 이유는 정규식이라는게 Unix 에서 만들어진 개념이기 때문이다. Unix 에서는 정규식을 그냥 '가져다' 쓰는 수준이다. 정규식 라이브러리(프로그램 만들때 가져다 쓰는 기능 도서관 개념)가 널려 있기 때문에 정규식 기능을 넣어 프로그램을 만드는 것 또한 식은죽 먹기다. (Unix 쓰는 컴쟁이들은 골수 컴쟁이들이다. 컴쟁이 근성이 없으면 생존 자체가 불가능하기 때문이다. 윈도우처럼 떠먹여 주는 운영체제가 아니기 때문에...)
대두족장 정규식 편집기의 소스를 해독할 수 있는 분이라면 쉽게 느끼겠지만 내가 정규식 기능에 대해 구현한 건 단 한줄도 없다. Python 이란 언어도 Unix 기반으로 만들어져 있기 때문에 정규식 라이브러리가 기본으로 딸려 오기 때문이다. 그냥 가져다 쓰면 된다. 그러니까 대두족장 정규식 편집기는 Python 정규식 라이브러리를 가져다 쓰기 위한 껍데기에 지나지 않는다.
아쉽게도 윈도우에는 제대로된 정규식 라이브러리도 없고 있다해도 누군가 돈받고 파는 것들 뿐이라 (Unix 기반의 정규식 라이브러리는 100% 오픈소스에 공짜다. 그래서 나같은 놈이 걍 가져다 쓰는 거다. 품질도 왓따~) 윈도우 프로그램 만드는 개발자들이 골치를 썩는다. UltraEdit 만든 개발자도 마찬가지다. 정규식 기능을 나름대로 구현하다보니 여기저기 구멍이 뚫리고 원래 UltraEdit에 있는 기본 찾고 바꾸기 기능과 상충되는 부분도 있어 궁여지책으로 구겨넣은 감이 없지 않다는 말이다.
정규식을 지원하는 공짜 오픈소스 텍스트 에디터는 널려 있다. UltraEdit처럼 유료 에디터도 아니다.
그런데도 UltraEdit를 권하는 이유는 에디터의 기능만큼은 가장 뛰어나다고 보기 때문이다.
정규식을 알게 되면 정규식을 제대로 지원하는 에디터를 원하게 될 지도 모른다. 나중에 책에서는 그런 에디터를 모아 소개할 예정이다.
에디터 기능이 빵빵해야 하는게 아니라면 대두족장 정규식 편집기로도 못할 일 없다. 정규식은 100% 지원하니까...
반복 지정
예를 들어, 문서에서 네자리 숫자만 찾는다고 해보자. 지금까지 배운대로라면 다음처럼 해주면 쉽게 찾을 수 있다.
찾기 패턴: [0-9][0-9][0-9][0-9]
근데, 10자리 숫자를 찾는다면?
돌아버리는 찾기 패턴: [0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]
또, 짱구 굴려보자. 컴쟁이 마인드로...
컴쟁이들이 이거 찾아내겠는가? 100자리면 [0-9]를 백번 쓰란 말인가?
컴쟁이들은 이딴 거 절대 못참는다. 그럼 분명 컴쟁이들이 다른 기능을 만들어 뒀을 거다. 그게 바로 {} 를 활용한 반복 회수 지정이다.
컴쟁이 근성 찾기 패턴: [0-9]{4}
이러면 숫자 4자리수를 찾는다. 반복 회수를 {} 안에 지정해주면 된다. 한발 더 나아가, 최소 반복 회수와 최대 반복 회수를 지정할 수도 있다. 예를 들어, 4자리에서 10자리 숫자까지 몽땅 찾으려면 이렇게 한다.
컴쟁이 근성 찾기 패턴: [0-9]{4,10}
{최소반복회수, 최대반복회수} 로 지정해주면 된다는 말이다.
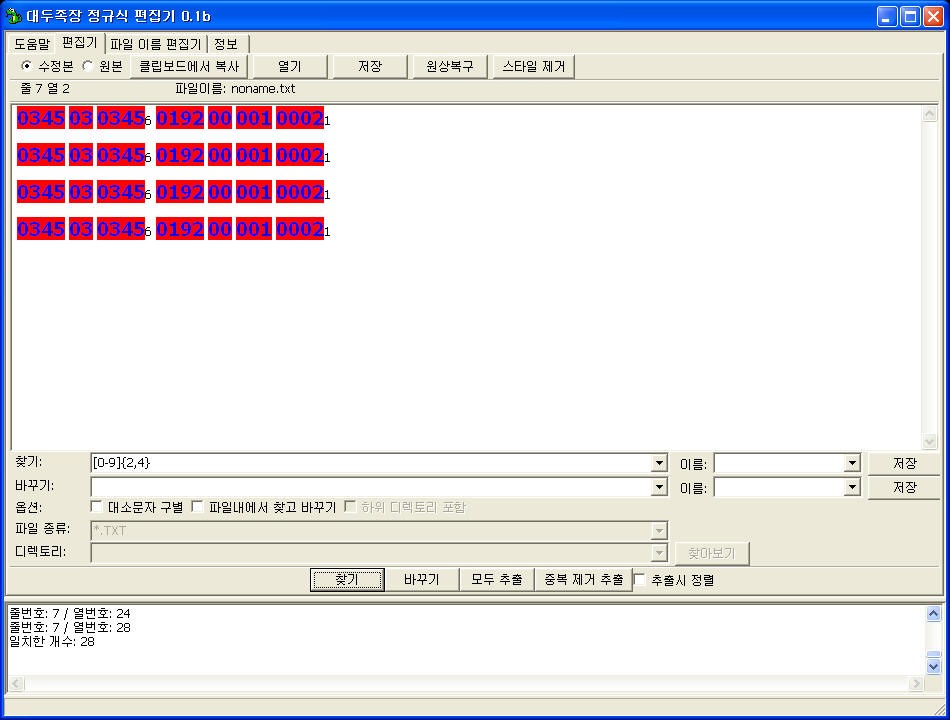
2자리에서 4자리숫자까지 잘 찾는가 싶었는데 아쉽게도 5자리 숫자의 일부분까지 찾아버린다.
정규식 처음 배우면 이런데서 좌절감을 느낀다. 딱 2자리, 3자리, 4자리 숫자만 찾고 싶은데 5자리 숫자라는게 알고보면 4자리숫자+1자리 숫자인거니 앞부분의 4자리 숫자까지 찾는거다.
물론, 여러가지 짱구를 굴려 이렇게 엉뚱한 패턴을 찾는 걸 방지할 수 있다.
예를 들어, 문서 패턴을 보면 숫자 다음에 공백이 나오므로 [0-9]{2,4} 처럼 정규식 찾기 패턴에도 공백을 붙여주면 된다. 그런데, 이럴 경우 이번엔 5자리 숫자에서 앞부분 4자리가 아니라 뒷부분 4자리를 찾는다. 짜증나기 시작한다ㅡ.ㅡ
좀더 짱구를 굴리면 정규식 찾기 패턴의 앞뒤로 공백을 넣어주면 될거다. 근데 이 경우는 또 2~4 자리 숫자가 줄 맨앞에 나와 앞에 공백이 없는 경우는 찾지 않는다. 물론, 여기서도 | 문자를 써서 패턴을 일일이 경우의 수로 만들어 줄 수도 있지만, 이것 역시 컴쟁이라면 안할 짓 아닌가? 컴쟁이들은 그런거 못참으니까...
그래서 만들어진게 단어 구분자(word boundary) 라는 거다. 예를 들어, 다음 문장을 단어 구분자만 고려해 엑스레이 찍어보면 이렇게 돼 있다.
나는 대두족장이다. 너는?
[wb]나는[wb]대두족장이다[wb][wb]너는[wb]
단어를 구분하는 문자는 가장 먼저 줄의 시작(^), 줄의 끝($), 공백( ), 문자 이외의 기호들(?.,[],{},() 등등)이 된다.
이걸 몽땅 합쳐서 지정할 수 있는 정규식 기호가 바로 \b 이다. (정규식을 지원하는 프로그램에 따라 \< \> 기호를 사용해 단어의 시작과 끝을 나타내는 경우도 있지만 \b가 일반적이다. 또, \B라고 하면 정반대로 단어의 일부만 찾는다.)
그러니까 앞에 나온 숫자의 예에서는 단어 구분을 해주면 제대로 찾는다는 말이다.
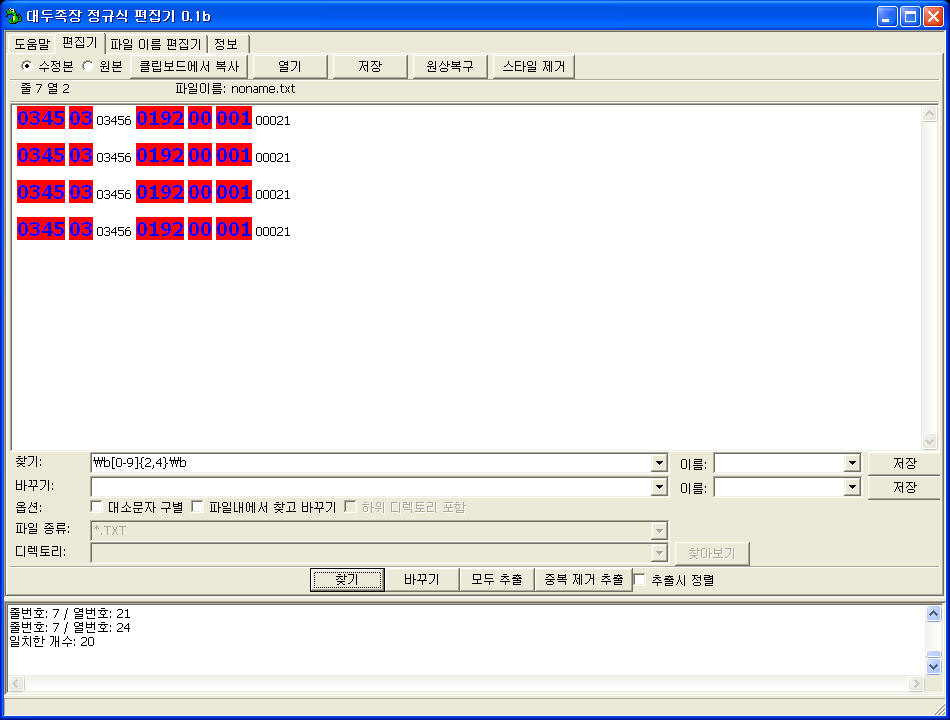
뽕빨 컴쟁이 근성 찾기 패턴: \b[0-9]{4,10}\b
지름길
컴쟁이들은 뭐든지 길어지는 거 엄청 싫어한다. 그래서 핫키라는 걸 만들고 바로가기 숏컷을 만드는 거다.
정규식에도 그런게 있다. (이건 UltraEdit에서도 적용된다.)
이미 앞에서 일부는 언급했다. 지름길을 뽕빨 내보자.
\d - 숫자 (digit). [0-9] 의 지름길.
\D - 숫자 이외의 문자 (Digit). [^0-9]의 지름길. 또는 [^\d]와 같은말.
\w - 영문알파벳과 숫자를 포함한 일반문자 (한글은 문자취급 안한다). [a-zA-Z0-9]의 지름길.
\W - 영문알파벳과 숫자를 제외한 모든 문자 (한글도 여기 포함된다). 여기서 w는 whitespace의 약자로 서식의 의미를 의미를 갖는 공백, 탭, 줄바꿈문자 등등을 모두 포함한다. [^a-zA-Z0-9]의 지름길. 또는 [^\w]와 같은말.
\s - 공백문자와 일치. 공백문자를 영어로 whitespace character라고 한다. 공백문자라고 해서 달랑 공백만 해당하는 게 아니라 탭, 줄바꿈 문자를 포함해 자리는 차지하는데 문자로서의 가치가 없고 서식 기능만 하는 문자를 가리킨다. [ \n\r\t] 의 지름길이라고 생각하면 된다.
\S - \s 의 정반대다. 공백문자 이외의 모든 문자를 말한다. [^\s]와 같은 말이다.
이 지름길만 알아도 정규식이 무쟈게 짧아진다. 한글이 포함된 줄 찾기 패턴 기억하시는가? 그걸 지름길로 표현해보자.
한글줄 찾기 패턴: ^[^a-zA-Z0-9]+$|^[a-zA-Z0-9]+[^a-zA-Z0-9]+$
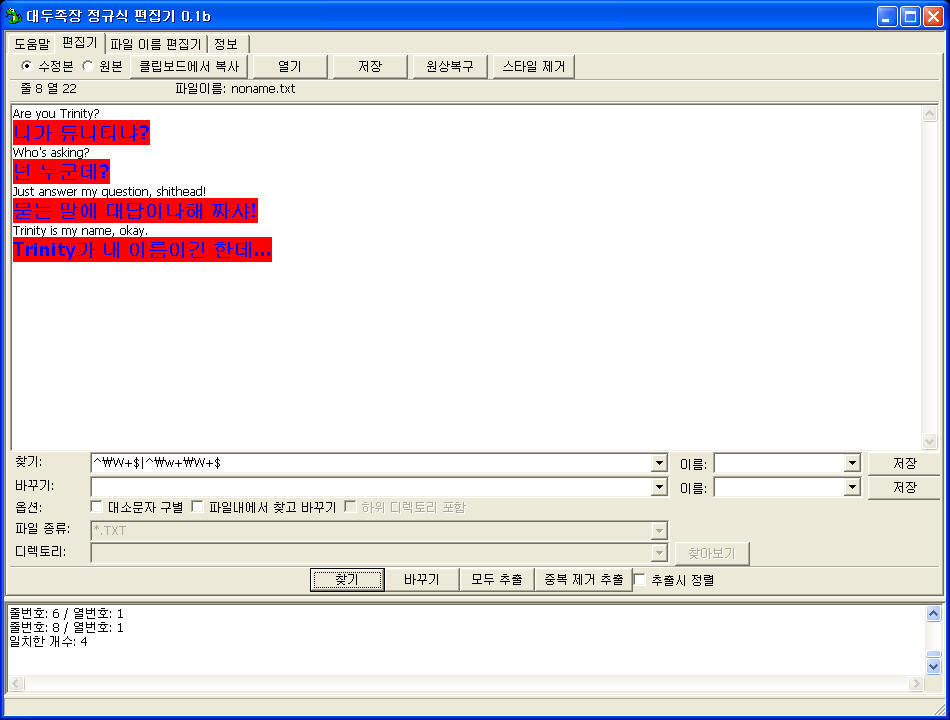
한글줄 찾기 패턴 단축 버전: ^\W+$|^\w+\W+$
훨씬 간결하지만 결과는 똑같다.
간결성과 가독성
간결하다고 다 좋은 거 아니다. 정규식처럼 조금만 길어져도 난수표가 되기 쉬운 기능은 길더라도 차라리 한눈에 읽기 편한 방법으로 작성하는 게 오히려 나을 수 있다는 거다. 정규식에 꽤 익숙해지기 전까지는 간결성보다 가독성 위주로 패턴 작성을 하는게 좋다.
한글 줄 찾기 패턴만 보더라도 짧은 게 있어보이기는 하지만^^ 아쉽게도 시간이 꽤 흐른다음 저걸 해독하려면 처음에 나온 긴~ 버전이 훨씬 가독성이 좋다.
한가지 실험을 해보자. \s 가 공백문자(탭, 공백, 줄바꿈 등)를 가리킨다고 했으니 앞에 나온 2~4자리 숫자 찾아내기 패턴에 응용할 수 있지 않을까?
실험 패턴: \s[0-9]{2,4}\s
이렇게 말이다. 한번 찾아보자.
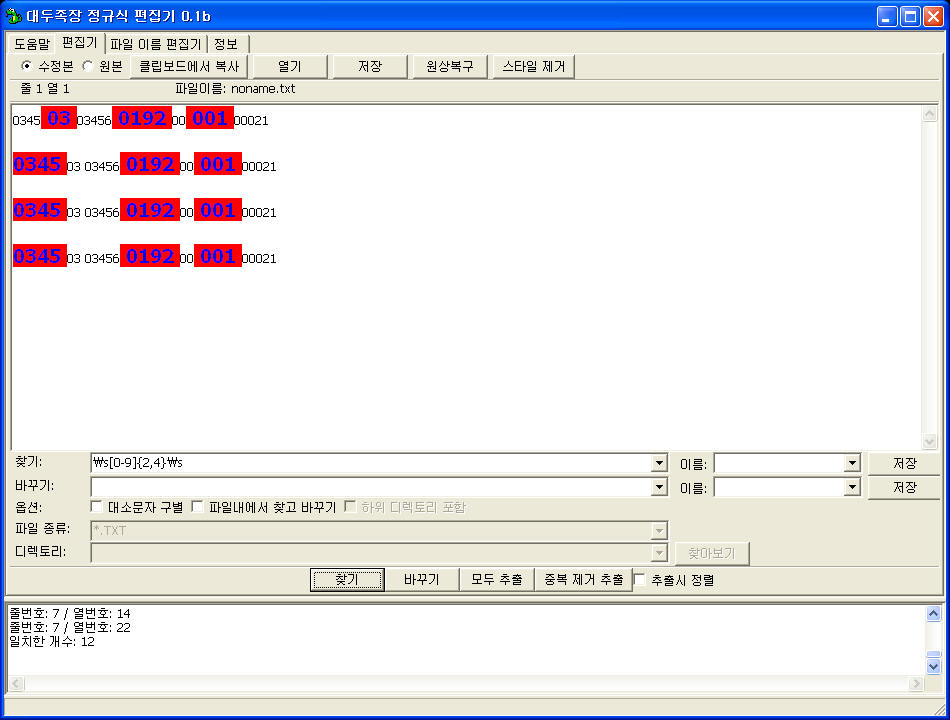
아쉽게도 모두 찾긴 하는데 가장 처음에 나오는 4자리 숫자를 찾지 못한다. 왜 그럴까?
가장 첫줄에 있는 0345 의 경우 앞에 공백문자가 없기 때문이다. \b 의 경우는 줄의 시작도 단어 구분으로 여거서 찾아낼 수 있지만 \s 의 경우는 단어 구분이 아니라 탭, 줄바꿈, 공백 등 공백 문자만 찾는다. 따라서 첫번째 줄 처음에 나오는 0345를 찾을 수 있으려면 그 앞에도 공백 문자가 있어야 한다. 엔터 한방 때려봐 주자.
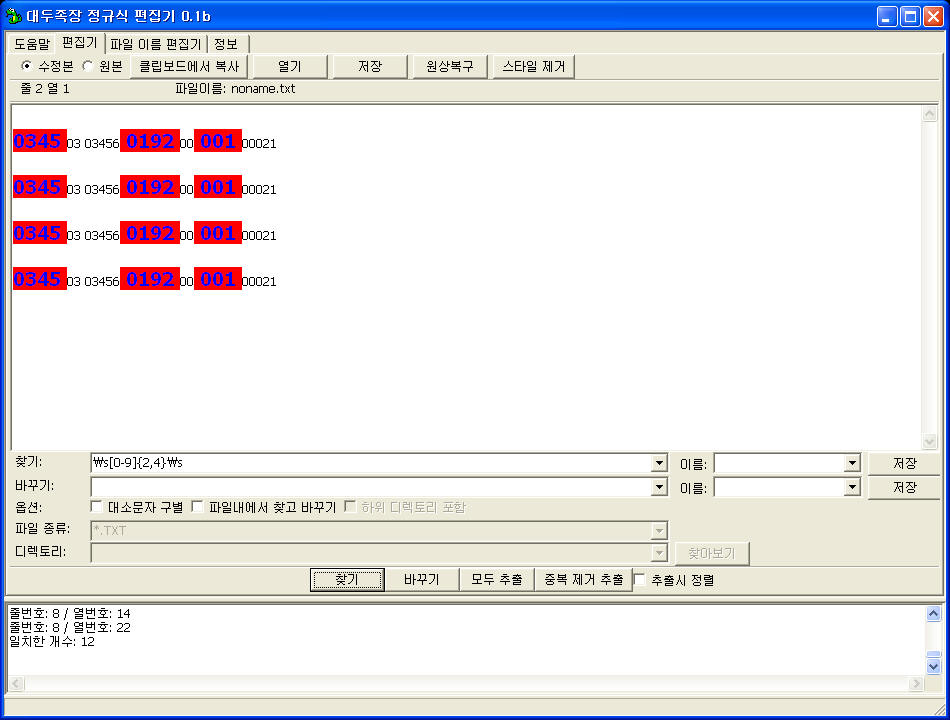
이제 제대로 찾는다. 억지로 공백 문자를 앞에나 하나 넣어줬으니까 말이다. 이게 공백문자와 단어구분자의 차이다.
근데...
찾은 걸 잘 보면 또 한가지 차이가 있다. \s 는 공백문자를 포함해서 찾는다. \b의 경우는 단어 구분을 해서 단어가 시작되는 부분부터 찾기 때문에 다른 문자가 포함되지 않는다. 그러니까 \s 는 자리값이 있지만 \b는 없다는 말이다. 단지, 단어가 시작되는 부분만 표시해줄 뿐이다. 따라서, \b 를 사용한 숫자 찾기 패턴이 훨씬 효율적이다.
이제 삽질 얘기 끝났습니다 :-)
|
|
'JAVA > regex 정규표현식' 카테고리의 다른 글
| 정규표현식 관련 링크들 (0) | 2014.10.28 |
|---|---|
| [Java] Regex(자바에서 정규식 사용하기) (0) | 2014.10.28 |
| Perl/정규표현식 (0) | 2014.10.28 |
| 파이썬 정규 표현식 HOWTO (0) | 2014.10.28 |
| 패턴 추출 기능 추가 - Ver. 0.1b 프리뷰 (0) | 2014.10.28 |
| 대두족장 정규식 편집기 0.1a Preview (0) | 2014.10.28 |
| Ver. 0.1a - 대두족장 정규식 편집기 (0) | 2014.10.28 |
| 천단위 콤마 찍기 - 미리보기/돌아보기 기능 (0) | 2014.10.28 |

nineDeveloper
안녕하세요 현직 개발자 입니다 ~ 빠르게 변화하는 세상에 뒤쳐지지 않도록 우리모두 열심히 공부합시다 ~! 개발공부는 넘나 재미있는 것~!